.. _datasets:
10.49. 数据集¶
使用 dataset 和 datarep 关键字可以匹配大量数据到任何粘性缓冲区。
例如,匹配名为 dns-bl 的DNS黑名单:
dns.query; dataset:isset,dns-bl;
这些关键字支持转换操作。例如,通过MD5黑名单检查DNS查询:
dns.query; to_md5; dataset:isset,dns-bl;
10.49.1. 全局配置(可选)¶
数据集可以选择在主配置中定义。集合也可以通过规则语法声明。
跟踪唯一值的集合示例:
datasets:
ua-seen:
type: string
state: ua-seen.lst
dns-sha256-seen:
type: sha256
state: dns-sha256-seen.lst
与上述配置配套的规则:
alert dns any any -> any any (msg:"dns list test"; dns.query; to_sha256; dataset:isset,dns-sha256-seen; sid:123; rev:1;)
alert http any any -> any any (msg: "http user-agent test"; http.user_agent; dataset:set,ua-seen; sid:234; rev:1;)
还可以选择定义全局默认的memcap和hashsize。
示例:
datasets:
defaults:
memcap: 100mb
hashsize: 2048
ua-seen:
type: string
load: ua-seen.lst
或者为每个数据集单独定义memcap和hashsize。
示例:
datasets:
ua-seen:
type: string
load: ua-seen.lst
memcap: 10mb
hashsize: 1024
Note
hashsize 应接近数据集中的条目数量以避免冲突。如果设置过低,可能导致启动时间较长。
10.49.2. 规则关键字¶
10.49.2.1. dataset¶
数据集是二元的:数据要么在集合中,要么不在。
语法:
dataset:<cmd>,<name>,<options>;
dataset:<set|unset|isset|isnotset>,<name> \
[, type <string|md5|sha256|ipv4|ip>, save <file name>, load <file name>, state <file name>, memcap <size>, hashsize <size>
, format <csv|json|ndjson>, context_key <output_key>, value_key <json_key>, array_key <json_path>,
remove_key];
- type <type>
数据类型:string, md5, sha256, ipv4, ip
- load <file name>
Suricata启动时加载数据的文件名
- state
设置加载和保存数据集的文件名
- save <file name>
高级选项,设置Suricata退出时保存内存数据的文件名
- memcap <size>
相应数据集的最大内存限制
- hashsize <size>
相应数据集的哈希大小允许值
- format <type>
文件格式:csv, json。默认为csv。参见 dataset with json format 了解json 和ndjson选项
- context_key <key>
用于丰富警报事件的键 适用于json格式
- value_key <key>
用于警报值的键 适用于json格式
- array_key <key>
用于警报数组的键 适用于json格式
- remove_key
如果设置,将从警报事件中移除由value_key指向的JSON对象
Note
'type' 是必填项,必须设置。
Note
'load' 和 'state' 或 'save' 和 'state' 不能混用。
示例规则如下:
检测唯一的User-Agent:
alert http any any -> any any (msg:"LOCAL HTTP new UA"; http.user_agent; dataset:set,http-ua-seen, type string, state http-ua-seen.csv; sid:8000001; rev:1;)
检测唯一的TLD:
alert dns $HOME_NET any -> any any (msg:"LOCAL DNS unique TLD"; dns.query; pcrexform:"\.([^\.]+)$"; dataset:set,dns-tld-seen, type string, state dns-tld-seen.csv; sid:8000002; rev:1;)
下图展示了 pcrexform 如何在域名上工作以在数据集 dns-tld-seen 中找到TLD:
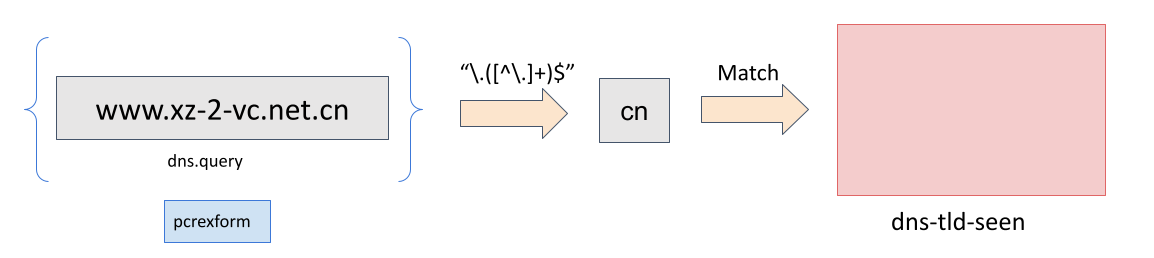
请注意,仅使用数据集无法完成某些操作(如上面的示例2),但可以结合其他规则关键字。不过要注意额外关键字的性能开销,例如在上面的第二个示例规则中,由于 pcrexform,可能会对性能产生负面影响。
10.49.2.2. datarep¶
数据信誉允许将数据与信誉列表进行匹配。
语法:
datarep:<name>,<operator>,<value>, \
[, load <file name>, type <string|md5|sha256|ipv4|ip>, memcap <size>, hashsize <size>];
示例规则如下:
alert dns any any -> any any (dns.query; to_md5; datarep:dns_md5, >, 200, load dns_md5.rep, type md5, memcap 100mb, hashsize 2048; sid:1;)
alert dns any any -> any any (dns.query; to_sha256; datarep:dns_sha256, >, 200, load dns_sha256.rep, type sha256; sid:2;)
alert dns any any -> any any (dns.query; datarep:dns_string, >, 200, load dns_string.rep, type string; sid:3;)
在这些示例中,DNS查询字符串被检查与三个不同的信誉列表:MD5列表、SHA256列表和原始字符串(缓冲区)列表。只有当数据在列表中且信誉值大于200时,规则才会匹配。
10.49.2.3. dataset with JSON¶
dataset with JSON 允许将数据与集合进行匹配,并在事件中输出与匹配值关联的数据。
支持两种格式:json 和 ndjson。区别在于 json 格式是单个JSON对象,而 ndjson 处理每行一个JSON对象的文件。ndjson 格式适用于大文件,因为解析是逐行进行的。
语法:
dataset:<cmd>,<name>,<options>;
dataset:<isset|isnotset>,<name> \
[, type <string|md5|sha256|ipv4|ip>, load <file name>, format <json|ndjson>, memcap <size>, hashsize <size>, context_key <json_key> \
, value_key <json_key>, array_key <json_path>];
示例规则如下:
alert http any any -> any any (msg:"IP match"; ip.dst; dataset:isset,bad_ips, type ip, load bad_ips.json, format json, context_key bad_ones, value_key ip; sid:8000001;)
在此示例中,如果目标IP在集合中,则会触发匹配,并且警报将包含一个 alert.content.bad_ones 子对象,其中包含与该值关联的JSON数据(bad_ones 来自 context_key 选项)。
当格式为 json 或 ndjson 时,value_key 用于获取行(ndjson 格式)或数组(json 格式)中的值。数据文件中至少需要有一个元素包含 value_key 才能成功加载。
如果存在 array_key,Suricata将提取对应的子对象(必须是JSON数组)并在该数组中搜索要添加到集合的元素。这仅适用于 json 格式。
如果不想在警报中包含 value_key,可以使用 remove_key 选项。这将从警报事件中移除该键。
更多信息请参见 Dataset with JSON format。
10.49.3. 规则重载¶
在yaml中定义的集合,或仅使用 state 或 save 的集合,被视为 动态 集合。这些集合在规则重载期间不会重新加载。
仅在规则中使用 load 定义的集合被视为 静态 测试。这些集合在运行时不应更改。在规则重载期间,这些集合会从磁盘重新加载。此重载在完整的规则重载过程完成后生效。
10.49.4. Unix Socket¶
10.49.4.1. dataset-add¶
Unix Socket命令,用于向集合添加数据。成功后,添加会立即生效。
语法:
dataset-add <set name> <set type> <data>
- set name
已定义数据集的名称
- type
数据类型:string, md5, sha256, ipv4, ip
- data
序列化形式的数据(字符串为base64,md5/sha256为十六进制表示,ipv4/ip为字符串表示)
示例将'google.com'添加到集合'myset':
dataset-add myset string Z29vZ2xlLmNvbQ==
10.49.4.2. dataset-remove¶
Unix Socket命令,用于从集合中移除数据。成功后,移除会立即生效。
语法:
dataset-remove <set name> <set type> <data>
- set name
已定义数据集的名称
- type
数据类型:string, md5, sha256, ipv4, ip
- data
序列化形式的数据(字符串为base64,md5/sha256为十六进制表示,ipv4/ip为字符串表示)
10.49.4.3. dataset-clear¶
Unix Socket命令,用于清除集合中的所有数据。成功后,清除会立即生效。
语法:
dataset-clear <set name> <set type>
- set name
已定义数据集的名称
- type
数据类型:string, md5, sha256, ipv4, ip
10.49.4.4. dataset-lookup¶
Unix Socket命令,用于测试数据是否在集合中。
语法:
dataset-lookup <set name> <set type> <data>
- set name
已定义数据集的名称
- type
数据类型:string, md5, sha256, ipv4, ip
- data
测试数据的序列化形式(字符串为base64,md5/sha256为十六进制表示,ipv4/ip为字符串表示)
示例测试'google.com'是否在集合'myset'中:
dataset-lookup myset string Z29vZ2xlLmNvbQ==
10.49.4.5. dataset-dump¶
Unix socket命令,触发将数据集转储到磁盘。
语法:
dataset-dump
10.49.4.6. dataset-add-json¶
Unix Socket命令,用于向集合添加数据。成功后,添加会立即生效。
语法:
dataset-add-json <set name> <set type> <data> <json_info>
- set name
已定义数据集的名称
- type
数据类型:string, md5, sha256, ipv4, ip
- data
序列化形式的数据(字符串为base64,md5/sha256为十六进制表示,ipv4/ip为字符串表示)
示例将'google.com'添加到集合'myset':
dataset-add-json myset string Z29vZ2xlLmNvbQ== {"city":"Mountain View"}
10.49.5. 文件格式¶
数据集使用简单的CSV格式,每行一个数据。
10.49.5.1. 数据类型¶
- string
文件中为base64编码的字符串
- md5
文件中为十六进制编码的字符串
- sha256
文件中为十六进制编码的字符串
- ipv4
文件中为字符串
- ip
文件中为字符串,可以是IPv6或IPv4地址(标准表示法或IPv4 in IPv6表示法)
10.49.5.2. dataset¶
数据集结构简单,文件中每行一个数据。
语法:
<data>
例如,ua-seen类型为string:
TW96aWxsYS80LjAgKGNvbXBhdGlibGU7ICk=
通过 base64 -d 解码后显示其值:
Mozilla/4.0 (compatible; )
10.49.5.3. datarep¶
datarep格式与dataset类似,但多一个CSV字段:
语法:
<data>,<value>
10.49.5.4. dataset with JSON enrichment¶
如果 format json 用于dataset关键字的参数中,则加载的文件必须包含有效的JSON对象。
如果存在 value_key 选项,则文件必须包含一个有效的JSON对象,其中包含一个数组,且该数组中存在与 value_key 值相等的键。
例如,如果文件 file.json 如下所示(类似于REST API调用的返回):
{
"time": "2024-12-21",
"response": {
"threats":
[
{"host": "toto.com", "origin": "japan"},
{"host": "grenouille.com", "origin": "french"}
]
}
}
那么检查威胁列表的dataset with JSON可以定义为:
http.host; dataset:isset,threats,load file.json, context_key threat, value_key host, array_key response.threats;
如果签名匹配,将生成如下警报:
{
"alert": {
"context": {
"threat": {
"host": "toto.com",
"origin": "japan"
}
}
}
}
10.49.6. 文件位置¶
在 suricata.yaml 中配置的数据集文件名可以存在于文件系统的任何位置。
当在规则中指定数据集文件名时,适用以下 规则:
对于
load,文件名相对于包含该规则的规则文件打开。允许绝对文件名和父目录遍历。对于
save和state,文件名相对于$LOCALSTATEDIR/suricata/data。在许多安装中,这将是/var/lib/suricata/data,但运行suricata --build-info并检查--localstatedir的值以验证您安装中的位置。除非配置参数
datasets.allow-absolute-filenames设置为true,否则不允许绝对文件名或包含父目录遍历(..)的文件名。
10.49.7. 安全性¶
由于数据集可能允许规则分发者通过 save 和 state 数据集规则对系统进行写访问,默认情况下允许的位置是严格的,但有两个数据集选项可以调整使用数据集文件名的规则的安全性:
datasets:
rules:
# 设置为true以允许在规则中使用绝对文件名和包含".."组件的文件名引用父目录。
allow-absolute-filenames: false
# 允许规则中的数据集对"save"和"state"进行写访问。默认启用,但写访问仅限于数据目录。
allow-write: true
通过将 datasets.rules.allow-write 设置为false,所有 save 和 state 规则将无法加载。此选项默认启用以保持与之前Suricata 6.0版本的兼容性,但可能在未来的主要版本中更改。
通过将 datasets.rules.allow-absolute-filenames 设置为 true,可以恢复Suricata 6.0.13之前的行为,但这样做将允许任何规则覆盖系统上Suricata具有写访问权限的任何文件。